Manufacturing Research Agents — Multi-Agent Orchestration with Verification
I built this for my work with a Boston AI venture foundry that turns early ideas into manufacturing- and industrial-AI startups. Going from a raw idea to a product direction means fast, honest research — what already exists, what is defensible, and what is just hype — and a confident-sounding but wrong finding is worse than no finding when it is about to inform a product bet. This is a multi-agent system that does that triage: a manager decomposes a research question, parallel specialist workers research each strand, an independent verifier adversarially checks every claim, and anything uncertain is flagged for a human before it reaches a decision. It is built on the Anthropic Claude API.
Where it fits
At the foundry the unit of work is an idea — is there a real product here? Answering that means scanning prior art, who is already doing it, the underlying technical claim, and the market, and then trusting the result enough to act on it. Most “AI agent” demos stop at a single model call in a loop, which is exactly where that trust breaks down. So I built the parts that make a multi-agent system actually trustworthy — decomposition, parallel specialists, independent verification, observability, and an explicit escalate-to-human path — and put them around a real research workflow. The example questions are manufacturing-AI ones, but the pattern is general.
This is the agentic-AI piece of a portfolio that also includes my ES 51 design-to-build-to-monitor demos: the Additive Build Advisor and the companion runtime twin.
How it works
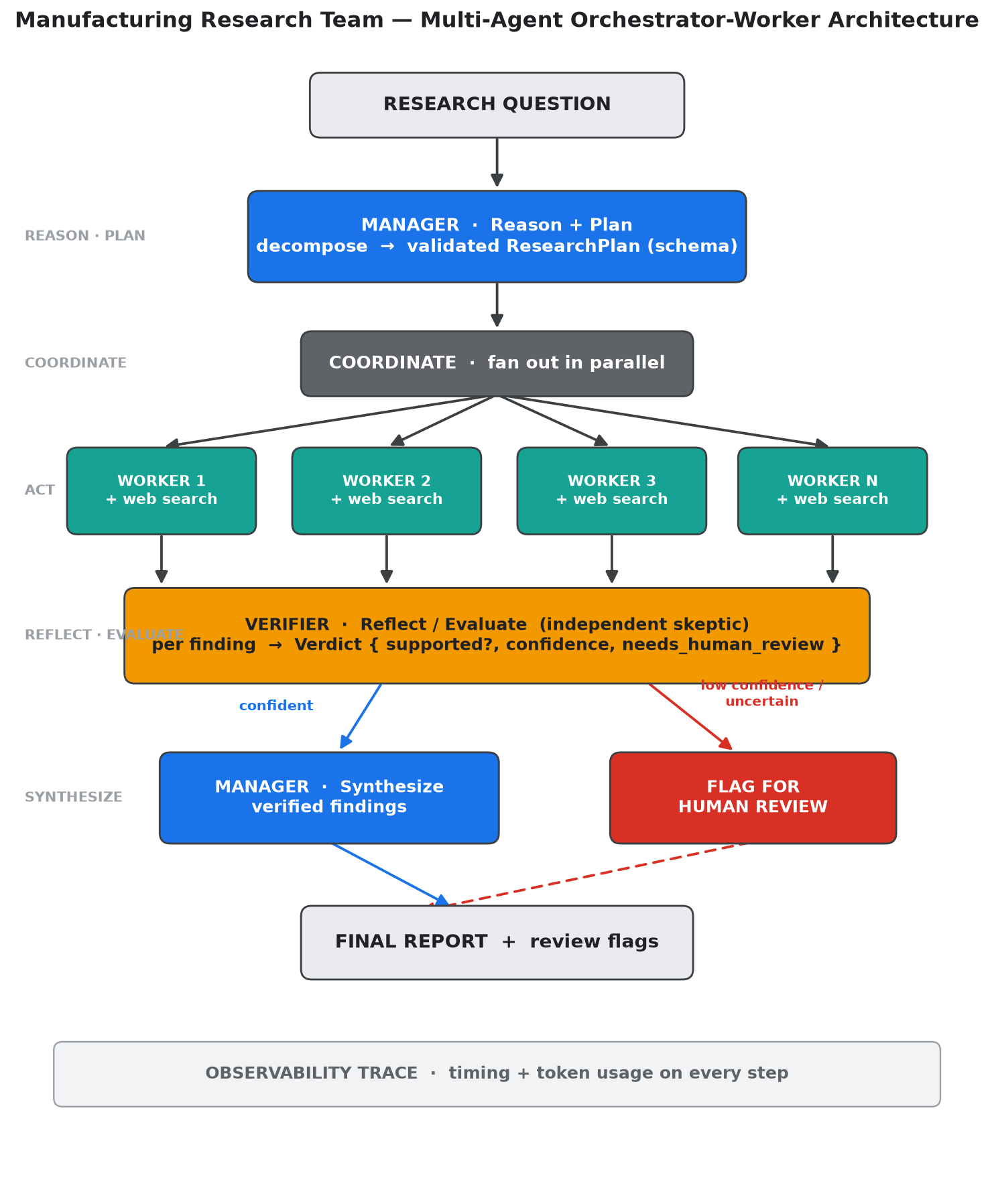
The flow reads decompose → fan out → verify → synthesize:
- Manager — plan. The manager interprets the question and decomposes it into independent, non-overlapping sub-topics. The plan is a schema-validated structured output, not prose I parse afterward — reliability comes from the contract.
- Workers — research, in parallel. Each specialist worker researches one sub-topic using the web-search tool and returns findings with sources. Workers run concurrently, so wall-clock time is the slowest worker, not the sum.
- Verifier — adversarial check. An independent verifier checks each finding against its sources and emits a validated verdict: is the claim supported, with what confidence, and does it need human review? A finding’s author is the worst judge of it, so the verifier is a separate skeptic, not self-review.
- Manager — synthesize. The manager assembles the verified findings into one report, told to caveat the shaky strands rather than lean on them.
- Human handoff. Low-confidence or weakly sourced findings are escalated rather than silently trusted — a person spends judgment on the genuinely uncertain calls instead of on first-pass scanning.
Throughout, an observability trace records every step’s timing and token usage. Without that, a multi-agent system is a black box you can’t debug or cost, so the trace is first-class rather than an afterthought.
The pattern, deliberately
The architecture follows a published framework on purpose: the agent lifecycle and trust pillars from Snowflake’s A Practical Guide to AI Agents — Sense → Reason → Plan → Coordinate → Act → Learn, plus Guardrails, Evaluation, and Observability. Mapping each module to a named stage kept me honest about which trust property each piece actually delivers, instead of asserting “it’s an agent” and stopping there.
Two choices carry most of the weight. Structured outputs are schema-validated where code consumes them (the plan and the verdicts) and left as prose where a human or the synthesizer reads them — forcing a schema on worker research would add complexity for no benefit. And verification is a separate agent, because an independent skeptic catches the plausible-but-wrong claims that self-review rubber-stamps.
There is also an LLM-gateway variant that runs the same orchestrator-worker pattern without an Anthropic key, requesting structured output via JSON prompting and validating it against the same schemas, falling back to human-review on a parse failure.
A sample run

Each finding carries its verdict and confidence; the verifier’s flags surface at the end, so the uncertain strands are visible rather than buried in a confident-sounding report.
Honest scope
This is a focused, readable demonstration of the pattern — not a production deployment. It intentionally omits prompt caching, retry/backoff beyond SDK defaults, persistence, access control, and a full evaluation harness. Each of those attaches at an obvious seam, which the architecture doc names; I’d rather show the pattern clearly than bury it under production scaffolding.
Code
The full system, the architecture write-up with the lifecycle mapping, an end-to-end sample transcript, and the gateway variant are on GitHub.